

实验报告格式根据 智能算法综合实践 课程要求。
比赛界面:电话顾客流失
我的开源 jupyter notebook :
一、前言 #
我想将 jupyter notebook 的输出汇总到本报告之中,但转化无法避免的导致排版略显杂乱,请理解。
本实验报告很大一部分是由 jupyter notebook 转化 md 而得到的:
jupyter nbconvert name.ipynb --to markdown
而 word 版本使用了:
pandoc name.md -o output.docx
比赛界面:Telco-Customer-Churn
二、实验目的 #
在 Kaggle 电话客户流失竞赛中构建模型并优化性能。
掌握数据预处理、特征工程及分类任务建模方法。
熟悉 PyTorch 的基本操作,包括数据处理、模型训练与评估。
其中关于 PyTorch 操作,借由本次实验我进行了一定程度的总结,见我的博客:pytorch 总结
三、实验原理与实验步骤 #
逻辑回归与数据处理 #
本实验使用的是 Telco 客户流失预测数据集,目标是预测客户是否会流失(分类任务)。
初步处理过程如下:
- 数据加载与探索:读取训练集和测试集,并查看数据维度、字段信息,识别出类别与数值型特征。
- 缺失值处理与特征编码:
- 类别特征使用
OneHotEncoder进行独热编码; - 数值特征使用
StandardScaler进行标准化; - 标签
Churn转换为二值标签(Yes → 1,No → 0)。
- 类别特征使用
- 主成分分析(PCA):
- 对预处理后的特征进行 PCA 降维,保留 95% 信息;
- 并可视化前两个主成分,观察数据分布。
使用 MLP 多层感知机模型 #
构建了一个包含两层隐藏层的 MLP 模型,结构为:
- 输入层 → Linear(64) → ReLU → Dropout(0.5)
- 隐藏层 → Linear(64) → ReLU → Dropout(0.5)
- 输出层 → Sigmoid
使用 BCELoss() 作为损失函数,采用 Adam 优化器进行训练。
最终训练准确率约为 0.8575,测试准确率为 0.8119。由于模型较大,出现了一定程度的过拟合。
随机森林模型 #
使用 RandomForestClassifier 进行建模:
- 设置参数如
n_estimators=150,max_depth=30。 - 并使用
GridSearchCV进行参数网格搜索,提升模型性能。
最终测试集准确率约为 0.7999。
SVM 支持向量机模型 #
采用 SVM 进行建模:
- 使用
PCA降维后的数据。 - 使用
SVC(kernel='linear', C=0.5),并通过GridSearchCV搜索最优参数。
最终测试集准确率约为 0.8204,表现稳定。
模型融合(Ensemble) #
为了进一步提升准确率,使用了融合模型:
- 加载 MLP、RandomForest 和 SVM 三个模型;
- 构建一个
WeightedEnsemble融合层,使用 softmax 归一化可学习权重; - 使用
BCELoss和 Adam 优化器训练融合模型; - 结果可视化显示融合层输出分布良好。
最终融合模型在测试集上取得 0.8421 的预测准确率 ,排名 25 / 300 。
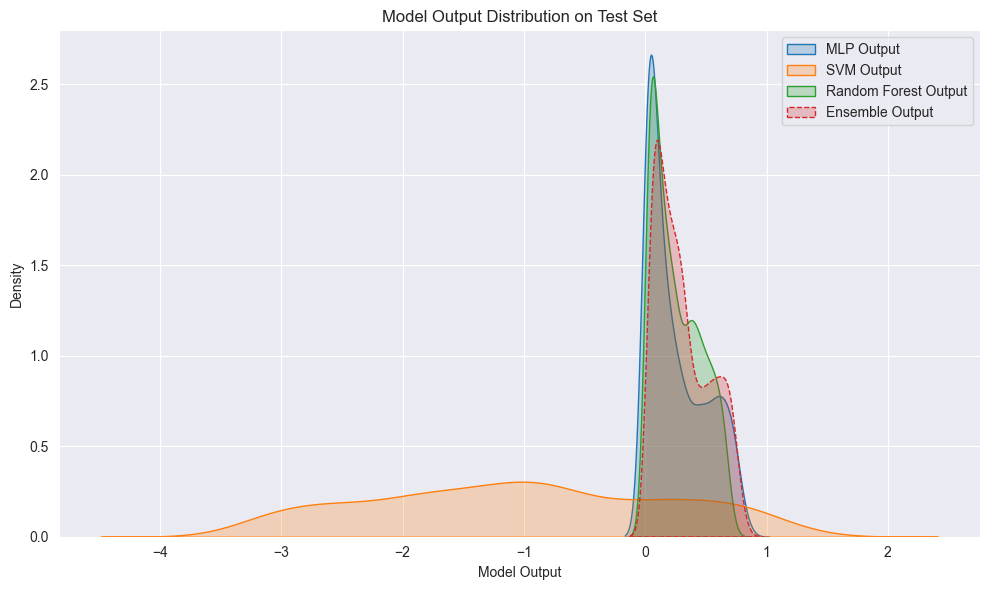
融合模型的训练和可视化展示了三种模型在预测上的互补性。
四、具体实验 #
导入并处理数据集 #
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
path = ""
E:\Softwares\anaconda\envs\RL\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
cuda
import numpy as np
import pandas as pd
import os
train_file = os.path.join(path, "dataset/WA_Fn-UseC_-Telco-Customer-Churn.csv")
test_file = os.path.join(path, "dataset/u-churn-test.csv")
train_df = pd.read_csv(train_file)
test_df = pd.read_csv(test_file)
print(train_df.shape)
print(test_df.shape)
print("Train Data Columns:")
print(train_df.columns.tolist())
(7043, 21)
(1409, 20)
Train Data Columns:
['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Churn']
print("\nTrain Data Description:")
print(train_df.describe())
Train Data Description:
SeniorCitizen tenure MonthlyCharges
count 7043.000000 7043.000000 7043.000000
mean 0.162147 32.371149 64.761692
std 0.368612 24.559481 30.090047
min 0.000000 0.000000 18.250000
25% 0.000000 9.000000 35.500000
50% 0.000000 29.000000 70.350000
75% 0.000000 55.000000 89.850000
max 1.000000 72.000000 118.750000
可以看到,数据集的范围不大。在这种情况下特征工程的意义并不大。
from sklearn.preprocessing import OneHotEncoder, StandardScaler
# 拆分训练特征和标签
X_train = train_df.drop(columns=['customerID', 'Churn'])
y_train = train_df['Churn'].map({'Yes': 1, 'No': 0}) # 将 Churn 转换为 0/1
# 从训练集中排除测试集中的 customerID(防止数据泄漏)
mask = ~train_df['customerID'].isin(test_df['customerID'])
X_train = X_train[mask]
y_train = y_train[mask]
df_with_target = X_train.copy()
df_with_target['target'] = y_train
corr_matrix = df_with_target.corr()
target_corr = corr_matrix['target'].drop('target')
top_10_corr = target_corr.abs().sort_values(ascending=False).head(10)
import seaborn as sns
import matplotlib.pyplot as plt
top_features = top_10_corr.index
plt.figure(figsize=(8, 6))
sns.heatmap(df_with_target[top_features].corr(), annot=True, cmap='YlGnBu', fmt=".2f")
plt.title("Top 3 Features Most Correlated with Target")
plt.tight_layout()
plt.show()
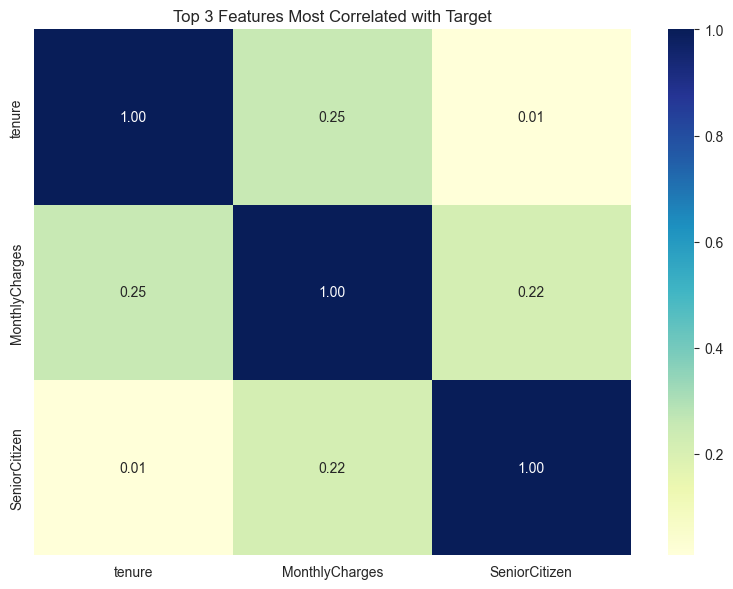
# 识别类别特征和数值特征
categorical_features = X_train.select_dtypes(include=['object']).columns
numerical_features = X_train.select_dtypes(exclude=['object']).columns
# 独热编码器
encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
X_train_cat_encoded = encoder.fit_transform(X_train[categorical_features])
X_train_cat_df = pd.DataFrame(X_train_cat_encoded, columns=encoder.get_feature_names_out(categorical_features))
# 合并数值特征与编码后的类别特征
X_train_final = pd.concat([X_train_cat_df, X_train[numerical_features].reset_index(drop=True)], axis=1)
# 标准化数值特征
scaler = StandardScaler()
X_train_final[numerical_features] = scaler.fit_transform(X_train_final[numerical_features])
# 处理测试集(与训练集相同方式)
X_test = test_df.drop(columns=['customerID'])
X_test_cat_encoded = encoder.transform(X_test[categorical_features])
X_test_cat_df = pd.DataFrame(X_test_cat_encoded, columns=encoder.get_feature_names_out(categorical_features))
X_test_final = pd.concat([X_test_cat_df, X_test[numerical_features].reset_index(drop=True)], axis=1)
X_test_final[numerical_features] = scaler.transform(X_test_final[numerical_features])
对热独立编码后的特征进行 pca
from sklearn.decomposition import PCA
# 将独热编码后的DataFrame转换为numpy数组
X_train_np = X_train_final.values
pca = PCA(n_components=0.95)
X_pca = pca.fit_transform(X_train_np)
# 转换为PyTorch张量
X_tensor = torch.tensor(X_pca, dtype=torch.float32)
y_tensor = torch.tensor(y_train.values.reshape(-1, 1), dtype=torch.float32)
X_test_pca = pca.transform(X_test_final.values)
X_test_tensor = torch.tensor(X_test_pca, dtype=torch.float32)
import matplotlib.pyplot as plt
# 提取前两个主成分
X_pca_2d = X_pca[:, :20]
# 创建散点图
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_pca_2d[:, 0], X_pca_2d[:, 1], c=y_train, cmap='viridis', alpha=0.7)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA 2D Visualization (95% Variance)')
plt.colorbar(scatter, label='Target')
plt.grid(True)
plt.tight_layout()
plt.show()
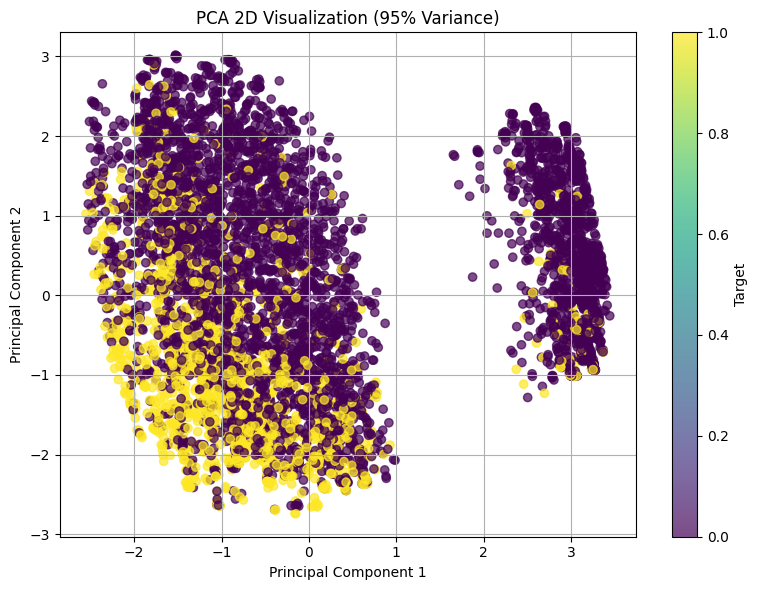
使用简单逻辑回归模型 #
import torch.nn as nn
import torch.optim as optim
# 逻辑回归模型
class ExpandedMLPModel(nn.Module):
def __init__(self, input_dim):
super(ExpandedMLPModel, self).__init__()
self.hidden1 = nn.Linear(input_dim, 64)
self.hidden2 = nn.Linear(64, 64)
self.output = nn.Linear(64, 1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.relu(self.hidden1(x))
x = self.dropout(x)
x = self.relu(self.hidden2(x))
x = self.dropout(x)
x = self.sigmoid(self.output(x))
return x
使用 BCELoss() 交叉熵作为损失函数。
import torch
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
import pandas as pd
num_epochs = 140
learning_rate = 0.0005
# 初始化模型
input_dim = X_pca.shape[1]
final_model = ExpandedMLPModel(input_dim)
criterion = nn.BCELoss()
optimizer = optim.Adam(final_model.parameters(), lr=learning_rate)
print("Training...")
train_losses = []
for epoch in tqdm(range(num_epochs), desc="Training"):
final_model.train()
optimizer.zero_grad()
outputs = final_model(X_tensor)
loss = criterion(outputs, y_tensor)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
final_model.eval()
with torch.no_grad():
test_outputs = final_model(X_test_tensor)
test_predictions = (test_outputs.numpy() > 0.43).astype(int) # 自定义阈值为 0.43
# 生成提交结果
result_df = pd.DataFrame({
'customerID': test_df['customerID'],
'Churn': test_predictions.flatten()
})
result_df['Churn'] = result_df['Churn'].map({1: 'Yes', 0: 'No'})
result_df.to_csv('output.csv', index=False)
print("预测结果已保存到 output.csv")
Training...
Training: 100%|██████████| 140/140 [00:07<00:00, 17.62it/s]
预测结果已保存到 output.csv
由于此数据集特征比较简单,因此出现了比较严重的过拟合。 一定的调参后好了一些。
# 保存模型参数
torch.save(final_model.state_dict(), 'logistic_regression_model.pth')
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
final_model.eval()
with torch.no_grad():
train_outputs = final_model(X_tensor)
train_predictions = (train_outputs.numpy() > 0.43).astype(int)
train_accuracy = accuracy_score(y_tensor.numpy(), train_predictions)
merged_df = train_df[['customerID', 'Churn']].merge(result_df, on='customerID', suffixes=('_true', '_pred'))
y_true = merged_df['Churn_true']
y_pred = merged_df['Churn_pred']
# 使用 LabelEncoder 转换 'Yes'/'No' 为 0/1
le = LabelEncoder()
y_true = le.fit_transform(y_true)
y_pred = le.transform(y_pred)
# 计算原始测试集准确率
original_test_accuracy = accuracy_score(y_true, y_pred)
plt.figure(figsize=(12, 5))
# 训练损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, label="Train Loss", color="blue")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Training Loss Curve")
plt.legend()
# 训练集 & 测试集准确率
plt.subplot(1, 2, 2)
plt.bar(["Train Accuracy", "Test Accuracy"],
[train_accuracy, original_test_accuracy],
color=["blue", "orange"])
plt.ylim(0, 1)
plt.ylabel("Accuracy")
plt.title("Train vs. Test Accuracy")
# 显示图像
plt.tight_layout()
plt.show()
# 打印准确率
print(f"最终训练集准确率: {train_accuracy:.4f}")
print(f"测试集准确率: {original_test_accuracy:.4f}")
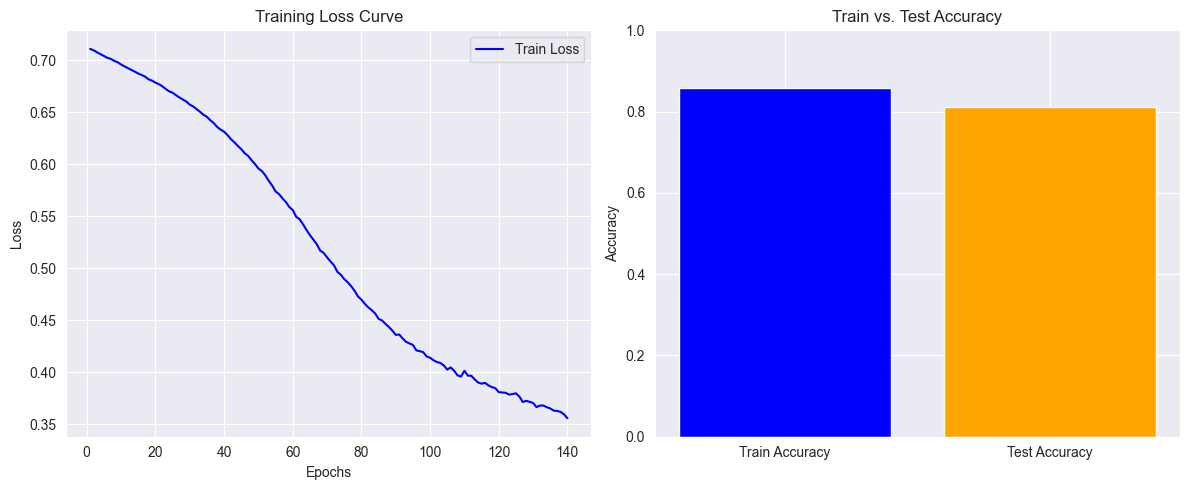
最终训练集准确率: 0.8575
测试集准确率: 0.8119
随机森林算法 #
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(
n_estimators=150,
max_depth=30,
min_samples_split=10,
min_samples_leaf=1,
max_features='sqrt',
random_state=42
)
rf_model.fit(X_train_final, y_train)
test_predictions = rf_model.predict(X_test_final)
result_df = pd.DataFrame({
'customerID': test_df['customerID'],
'Churn': test_predictions.flatten()
})
import joblib
joblib.dump(rf_model, 'random_forest_model.pkl')
print(result_df.head())
customerID Churn
0 1024-GUALD 1
1 0484-JPBRU 0
2 3620-EHIMZ 0
3 6910-HADCM 1
4 8587-XYZSF 0
GridSearchCV 搜索较优参数。
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 3, 5],
'max_features': ['sqrt', 'log2'],
'class_weight': ['balanced', None]
}
grid_search = GridSearchCV(
estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=2,
scoring='accuracy',
n_jobs=-1,
verbose=1
)
grid_search.fit(X_train_final, y_train)
best_model = grid_search.best_estimator_
print("最佳参数:", grid_search.best_params_)
Fitting 2 folds for each of 324 candidates, totalling 648 fits
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
merged_df = train_df[['customerID', 'Churn']].merge(result_df, on='customerID', suffixes=('_true', '_pred'))
y_true = merged_df['Churn_true']
y_pred = merged_df['Churn_pred']
# 使用 LabelEncoder 转换 'Yes'/'No' 为 0/1
le = LabelEncoder()
y_true = le.fit_transform(y_true)
# 计算准确率
original_test_accuracy = accuracy_score(y_true, y_pred)
print(f"测试集准确率: {original_test_accuracy:.4f}")
测试集准确率: 0.7999
SVM 算法 #
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
svm_clf = SVC(kernel='linear', C=0.5, gamma='scale')
svm_clf.fit(X_pca, y_train.values.ravel())
y_pred = svm_clf.predict(X_test_pca)
result_df = pd.DataFrame({
'customerID': test_df['customerID'],
'Churn': y_pred.flatten()
})
GridSearchCV 暴力参数
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': ['scale', 'auto', 0.01, 0.001],
'kernel': ['rbf', 'linear']
}
svc = SVC()
grid_search = GridSearchCV(estimator=svc, param_grid=param_grid, cv=2, scoring='accuracy', verbose=2, n_jobs=-1)
grid_search.fit(X_pca, y_train.values.ravel())
print("最佳参数组合:", grid_search.best_params_)
Fitting 2 folds for each of 32 candidates, totalling 64 fits
最佳参数组合: {'C': 0.1, 'gamma': 'scale', 'kernel': 'linear'}
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
import joblib
model_path = 'model/svm_model.pkl'
joblib.dump(svm_clf, model_path)
print(f"模型已保存到 {model_path}")
merged_df = train_df[['customerID', 'Churn']].merge(result_df, on='customerID', suffixes=('_true', '_pred'))
y_true = merged_df['Churn_true']
y_pred = merged_df['Churn_pred']
# 使用 LabelEncoder 转换 'Yes'/'No' 为 0/1
le = LabelEncoder()
y_true = le.fit_transform(y_true)
original_test_accuracy = accuracy_score(y_true, y_pred)
print(f"测试集准确率: {original_test_accuracy:.4f}")
模型已保存到 model/svm_model.pkl
测试集准确率: 0.8204
混合模型 #
读取 MLP、随机森林、SVM 三种模型。
input_dim = X_pca.shape[1]
model = ExpandedMLPModel(input_dim=input_dim)
model.load_state_dict(torch.load('model/logistic_regression_model.pth'))
<All keys matched successfully>
import joblib
rf_model = joblib.load("model/random_forest_model.pkl")
svm_clf = joblib.load("model/svm_model.pkl")
为三个模型的输出添加一个融合层。
import torch.nn as nn
class WeightedEnsemble(nn.Module):
def __init__(self):
super(WeightedEnsemble, self).__init__()
# 可学习的权重参数(初始化为相等)
self.weights = nn.Parameter(torch.ones(3))
self.sigmoid = nn.Sigmoid()
def forward(self, mlp_out, svm_out, rf_out):
# 拼接为一个 tensor: [N, 3]
all_outputs = torch.cat([mlp_out, svm_out, rf_out], dim=1)
# softmax 归一化权重
normalized_weights = torch.softmax(self.weights, dim=0)
weighted_sum = torch.matmul(all_outputs, normalized_weights.view(-1, 1))
return self.sigmoid(weighted_sum)
# MLP 模型输出
mlp_output = model(X_tensor).detach() # shape: [N, 1]
# SVM 输出
svm_output = torch.tensor(svm_clf.decision_function(X_pca).reshape(-1, 1), dtype=torch.float32)
# RF 输出
rf_output = torch.tensor(rf_model.predict_proba(X_train_final)[:, 1].reshape(-1, 1), dtype=torch.float32)
训练融合模型
from torch.utils.data import TensorDataset, DataLoader
ensemble_inputs = TensorDataset(mlp_output, svm_output, rf_output, y_tensor)
ensemble_loader = DataLoader(ensemble_inputs, batch_size=32, shuffle=True)
# 初始化融合模型
ensemble_model = WeightedEnsemble()
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(ensemble_model.parameters(), lr=0.01)
for epoch in range(20):
total_loss = 0
for mlp_out, svm_out, rf_out, labels in ensemble_loader:
optimizer.zero_grad()
outputs = ensemble_model(mlp_out, svm_out, rf_out)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 获取测试集的三个模型输出
mlp_test_out = model(X_test_tensor).detach()
svm_test_out = torch.tensor(svm_clf.decision_function(X_test_pca).reshape(-1, 1), dtype=torch.float32)
rf_test_out = torch.tensor(rf_model.predict_proba(X_test_final)[:, 1].reshape(-1, 1), dtype=torch.float32)
# 使用融合模型预测
ensemble_model.eval()
with torch.no_grad():
final_output = ensemble_model(mlp_test_out, svm_test_out, rf_test_out)
输出可视化,分别为三种模型的输出分布于散点图。
import matplotlib.pyplot as plt
import seaborn as sns
import torch
mlp_out = mlp_test_out.numpy().flatten()
svm_out = svm_test_out.numpy().flatten()
rf_out = rf_test_out.numpy().flatten()
ens_out = final_output.numpy().flatten()
# 可视化每个模型输出的分布
plt.figure(figsize=(10, 6))
sns.kdeplot(mlp_out, label='MLP Output', fill=True)
sns.kdeplot(svm_out, label='SVM Output', fill=True)
sns.kdeplot(rf_out, label='Random Forest Output', fill=True)
sns.kdeplot(ens_out, label='Ensemble Output', fill=True, linestyle='--')
plt.title('Model Output Distribution on Test Set')
plt.xlabel('Model Output')
plt.ylabel('Density')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 绘制 3D 散点图
sc = ax.scatter(
mlp_out, svm_out, rf_out,
c=ens_out,
cmap='coolwarm',
alpha=0.8,
edgecolors='k',
s=40
)
ax.set_xlabel('MLP Output')
ax.set_ylabel('SVM Output')
ax.set_zlabel('RF Output')
ax.set_title('3D Scatter of Base Model Outputs\n(Colored by Ensemble Output)')
cbar = fig.colorbar(sc, ax=ax, pad=0.1)
cbar.set_label('Ensemble Output')
plt.tight_layout()
plt.show()
C:\Users\walter\AppData\Local\Temp\ipykernel_29780\831797772.py:27: MatplotlibDeprecationWarning: Auto-removal of grids by pcolor() and pcolormesh() is deprecated since 3.5 and will be removed two minor releases later; please call grid(False) first.
cbar = fig.colorbar(sc, ax=ax, pad=0.1)
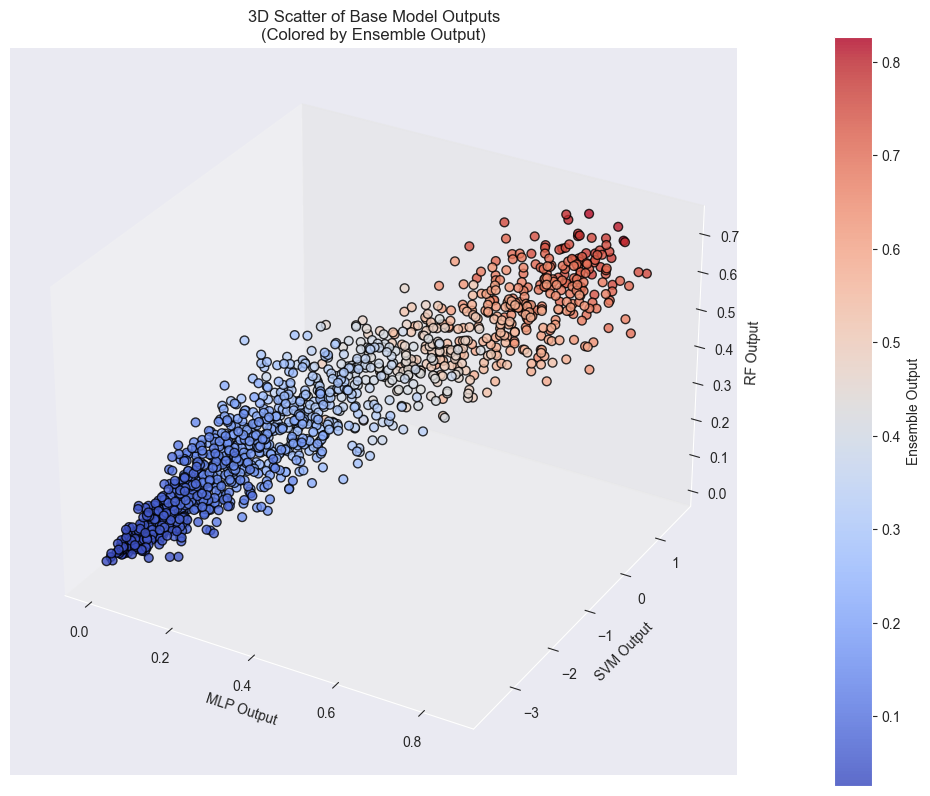
import pandas as pd
y_pred = final_output.numpy()
y_pred_class = (y_pred > 0.5).astype(int)
result_df = pd.DataFrame({
'customerID': test_df['customerID'].values,
'Churn': y_pred_class.flatten()
})
result_df.to_csv("final_predictions.csv", index=False)
print("预测结果已保存为 final_predictions.csv")
预测结果已保存为 final_predictions.csv
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
merged_df = train_df[['customerID', 'Churn']].merge(result_df, on='customerID', suffixes=('_true', '_pred'))
y_true = merged_df['Churn_true']
y_pred = merged_df['Churn_pred']
le = LabelEncoder()
y_true = le.fit_transform(y_true)
original_test_accuracy = accuracy_score(y_true, y_pred)
print(f"测试集准确率: {original_test_accuracy:.4f}")
测试集准确率: 0.8421
五、总结 #
本实验展示了从数据预处理、特征工程、模型设计与训练到融合策略的完整流程。
在实际项目中,融合模型不仅可以提高准确率,也提高了模型鲁棒性。
未来可以进一步尝试如 XGBoost、LightGBM、Stacking 等策略进一步提升模型表现。